Code author: jhkwakkel <j.h.kwakkel (at) tudelft (dot) nl>
example of use
We provide here an extended example of how prim can be used. As a starting point we use the cPickle file generated and saved in the tutorial on the Flu model. We use prim to find whether there are one or more subspaces of the uncertainty space that result in a high number of deaths for the ‘no policy’ runs.
To this end, we need to make our own classify(). This function should extract from the results, those related to the deceased population and classify them into two distinct classes:
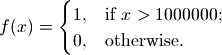
Here, 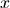 is the endstate of ‘deceased population region 1’.
is the endstate of ‘deceased population region 1’.
A second thing that needs to be done is to extract from the saved results only those results belonging to ‘no policy’. To this end, we can use logical indexing. That is, we can use boolean arrays for indexing. In our case, we can get the logical index in a straightforward way.
logicalIndex = experiments['policy'] == 'no policy'
We can now use this index to modify the loaded results to only include the experiments and results we want. The modified results can than be used as input for prim.
Together, this results in the following script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | import numpy as np
import matplotlib.pyplot as plt
import analysis.prim as prim
from expWorkbench import load_results
import expWorkbench.EMAlogging as EMAlogging
#perform_prim logs information to the logger
EMAlogging.log_to_stderr(level=EMAlogging.INFO)
def classify(data):
#get the output for deceased population
result = data['deceased population region 1']
#make an empty array of length equal to number of cases
classes = np.zeros(result.shape[0])
#if deceased population is higher then 1.000.000 people, classify as 1
classes[result[:, -1] > 1000000] = 1
return classes
#load data
results = load_results(r'../analysis/1000 flu cases.cPickle')
experiments, results = results
#extract results for 1 policy
logicalIndex = experiments['policy'] == 'no policy'
newExperiments = experiments[ logicalIndex ]
newResults = {}
for key, value in results.items():
newResults[key] = value[logicalIndex]
results = (newExperiments, newResults)
#perform prim on modified results tuple
boxes = prim.perform_prim(results, classify,
threshold=0.8,
threshold_type=1,
pasting=True)
#print prim to std_out
prim.write_prim_to_stdout(boxes)
#visualize
prim.show_boxes_individually(boxes, results)
prim.show_boxes_together(boxes, results)
plt.show()
|
which generates the following figures.
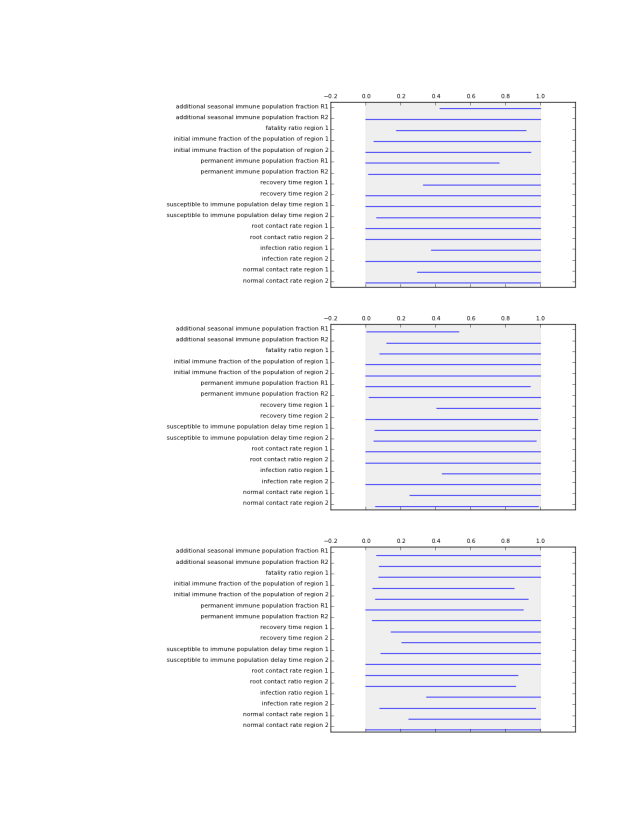
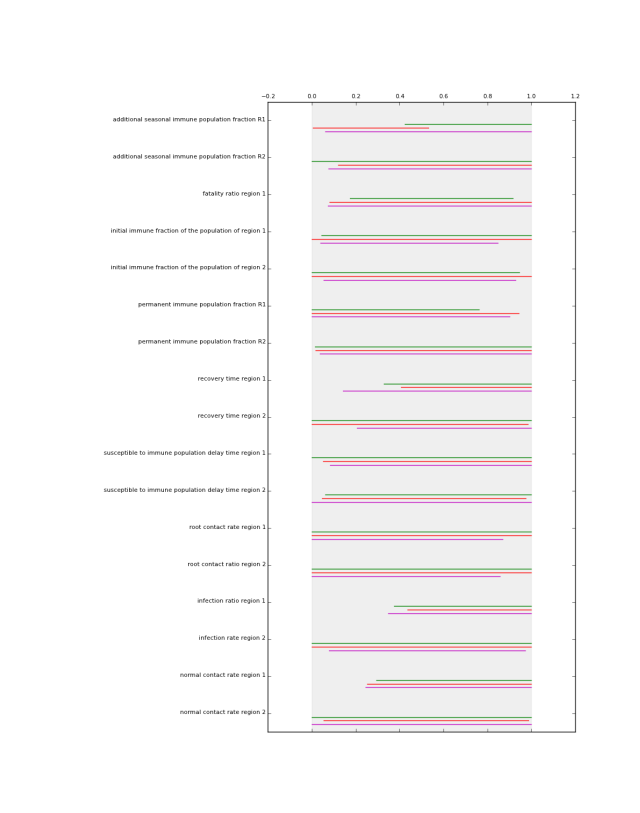
perform Patient Rule Induction Method (PRIM). This function performs the PRIM algorithm on the data. It uses a Python implementation of PRIM inspired by the R algorithm. Compared to the R version, the Python version is data type aware. That is, real valued, ordinal, and categorical data are treated differently. Moreover, the pasting phase of PRIM in the R algorithm is not consistent with the literature. The Python version is.
the PRIM algorithm tries to find subspaces of the input space that share some characteristic in the output space. The characteristic that the current implementation looks at is the mean of the results. Thus, the output space is 1-D, and the characteristic is assumed to be continuous.
As a work around, to deal with classes, the user can supply a classify function. This function should return a binary classification (i.e. 1 or 0). Then, the mean of the box is indicative of the concentration of cases of class 1. That is, if the specified threshold is say 0.8 and the threshold_type is 1, PRIM looks for subspaces of the input space that contains at least 80% cases of class 1.
| Parameters: |
|
|---|---|
| Returns: | a list of PRIM objects. |
for each box, the scenario discovery metrics coverage and density are also calculated:
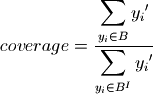
where 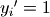 if
if 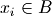 and
and 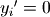 otherwise.
otherwise.
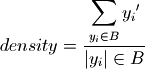
where if and
otherwise, and 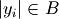 is the
cardinality of
is the
cardinality of 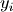 .
.
Density is the ratio of the cases of interest in a box to the total number of cases in that box. density is identical to the mean in case of a binary classification. For more detail on these metrics see Bryant and Lempert (2010)
references to relevant papers
ema application
Summary function for printing the results of prim to stdout (typically the console). This function first prints an overview of the boxes, specifying their mass and mean. Mass specifies the fraction of cases in the box, mean specifies the average of the cases.
| Parameters: |
|
|---|
if one wants to print these results to a file, the easiest way is to redirect stdout:
sys.stdout = open(file.txt, 'w')
This functions visually shows the size of a list of prim boxes. Each box is a single plot. The dump box is not shown. The size of the boxes is normalized, where 0 is the lowest sampled value for each uncertainty and 1 is the highest sampled value for each uncertainty. This is visualized using a light grey background.
| Parameters: |
|
|---|---|
| Return type: | a figure instance |
This functions visually shows the size of a list of prim boxes. Each box has its own color. The dump box is not shown. The size of the boxes is normalized, where 0 is the lowest sampled value for each uncertainty and 1 is the highest sampled value for each uncertainty. his is visualized using a light grey background.
| Parameters: |
|
|---|---|
| Return type: | a figure instance |
The default objective function used by PRIM. In the default implementation in peeling and pasting, PRIM selects the box that maximizes the average value of new_y. This function is called for each candidate box to calculate its average value:
![obj = \text{ave} [y_{i}\mid x_{i}\in{B-b}]](../_images/math/e8bd34e93409d3b85876f415d1ec5ae751e4e645.png)
where 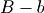 is the set of candidate new boxes.
is the set of candidate new boxes.
| Parameters: |
|
|---|
A test objective function to be used instead of the default objective function.
![obj = \frac
{\text{ave} [y_{i}\mid x_{i}\in{B-b}] - \text{ave} [y\mid x\in{B}]}
{|n(y_{i})-n(y)|}](../_images/math/37b89d1fd44d02e459ab8c8264b07dd6233991dc.png)
where is the set of candidate new boxes, 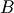 the old box
and
the old box
and 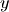 are the y values belonging to the old box.
are the y values belonging to the old box. 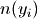 and
and 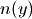 are the cardinality of and
respectively. So, this objective function looks for the difference between
the mean of the old box and the new box, divided by the change in the
number of data points in the box. This objective function offsets a problem
in case of categorical data where the normal objective function often
results in boxes mainly based on the categorical data.
are the cardinality of and
respectively. So, this objective function looks for the difference between
the mean of the old box and the new box, divided by the change in the
number of data points in the box. This objective function offsets a problem
in case of categorical data where the normal objective function often
results in boxes mainly based on the categorical data.
| Parameters: |
|
|---|